Data Virtualization by Ali Aghatabar (Founder & Director) @ Intelicosmos®, Aug 8, 2021
In this article, I will explain what Data Virtualization is, how different it is with legacy data & analytic platform and why Data Virtualization would be soon a new standard in data & analytic. Please check out below video for more information:
Before we explain Data Virtualization, let’s understand what are our current forms of data and analytic platforms:
Current Data & Analytic Principals/Techniques
For decades, we have been spending times and money on building different physical databases to onboard, message and develop analytical structures in order to help us analyse the data. There have been different milestones to this long journey, each came right after a new IT capability or invention by someone and for sure, there were always a right reason for them to became popular:
Data Warehousing
This is a long story and has been explored and architected in detail by people like Inmon, Kimball etc. Here is a definition of data warehouse from Wikipedia: “DWs are central repositories of integrated data from one or more disparate sources. They store current and historical data in one single place[2] that are used for creating analytical reports for workers throughout the enterprise”. Centralizing data has been one of the most important reason for data warehouses, but due to size, frequency and growth of data, Centralizing Data is not a priority anymore!Data Mart
Similar to data warehouse, data marts are built for analytical requirements, but data mart is more business oriented while data warehouse is an enterprise repository. Again, definition from Wikipedia: “The data mart is a subset of the data warehouse and is usually oriented to a specific business line or team. Whereas data warehouses have an enterprise-wide depth, the information in data marts pertains to a single department”. It clearly explains that data mart is a duplication of data sourced from data warehouse. Data Duplication is a wrong practice, and it has already caused a lot of miss-alignments in businesses.Staging
By looking at Wikipedia, we see that Staging environments are only Interim Environments to message data before it loaded into target data model which is normally a data warehouse or a data mart: “A staging area, or landing zone, is an intermediate storage area used for data processing during the extract, transform and load (ETL) process. The data staging area sits between the data source(s) and the data target(s), which are often data warehouses, data marts, or other data repositories”.Data Lake
Recently, Data Lake are introduced to be the raw data repository and help organizations for future analytics where raw & historical data is needed. While the essence of this theory is great, but organizations are normally enforced to introduce a new repository as a centralized Data Lake which enforces lots of ETLs and Data Duplications. Wikipedia: “A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files. A data lake is usually a single store of data including raw copies of source system data, sensor data, social data etc., and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning”.
With our current data growth and data producers like IoT devices, Data Lake looks to be a new norm for many organisations, whoever, having a Centralized and Physical Data Lake Repository has its own pros and cons. In case, if organization must move from one data lake strategy to another one, it means lots of jobs and huge impact on teams that are already consuming from current Data Lake.Indexing
Products like Apache Lucene and Google Search Engine, Elasticsearch, Splunk etc have introduced or used Data Indexing as alternatives to transactional analytic designs and the idea is more focused on keyword (whether an email address, a simple word like ‘data’, a unique record ID, etc) analytic and aggregations. Compared to technologies like Data Warehouse, Indexing has its own advantages and disadvantages. Being a schema less data model is an advantage while SQL query limitations is a disadvantage as an example. Wikipedia: “Search engine indexing is the collecting, parsing, and storing of data to facilitate fast and accurate information retrieval. Index design incorporates interdisciplinary concepts from linguistics, cognitive psychology, mathematics, informatics, and computer science.”
While Data Indexing started for Web Pages, but products like Elasticsearch have greatly used that for the purpose of analytic and machine learning. Microsoft has also combined the in-memory and indexing theories into its Vertipaq Engine used in Analysis Services or PowerBI.
While Indexing is a great way of building automatic data modelling in a cheap storages, but that is still unable to solve all sorts of analytic requirements and there are limitations like complex SQLs.
Except with Indexing, ETL is almost a key player and data is duplicated into many layers, even though the data model changes, but the same data context is copied from one to another one. This practice is very complex, expensive and takes time and many organizations have found it very hard and expensive to maintain and they also get deprecated over the time due to changes in business requirements.
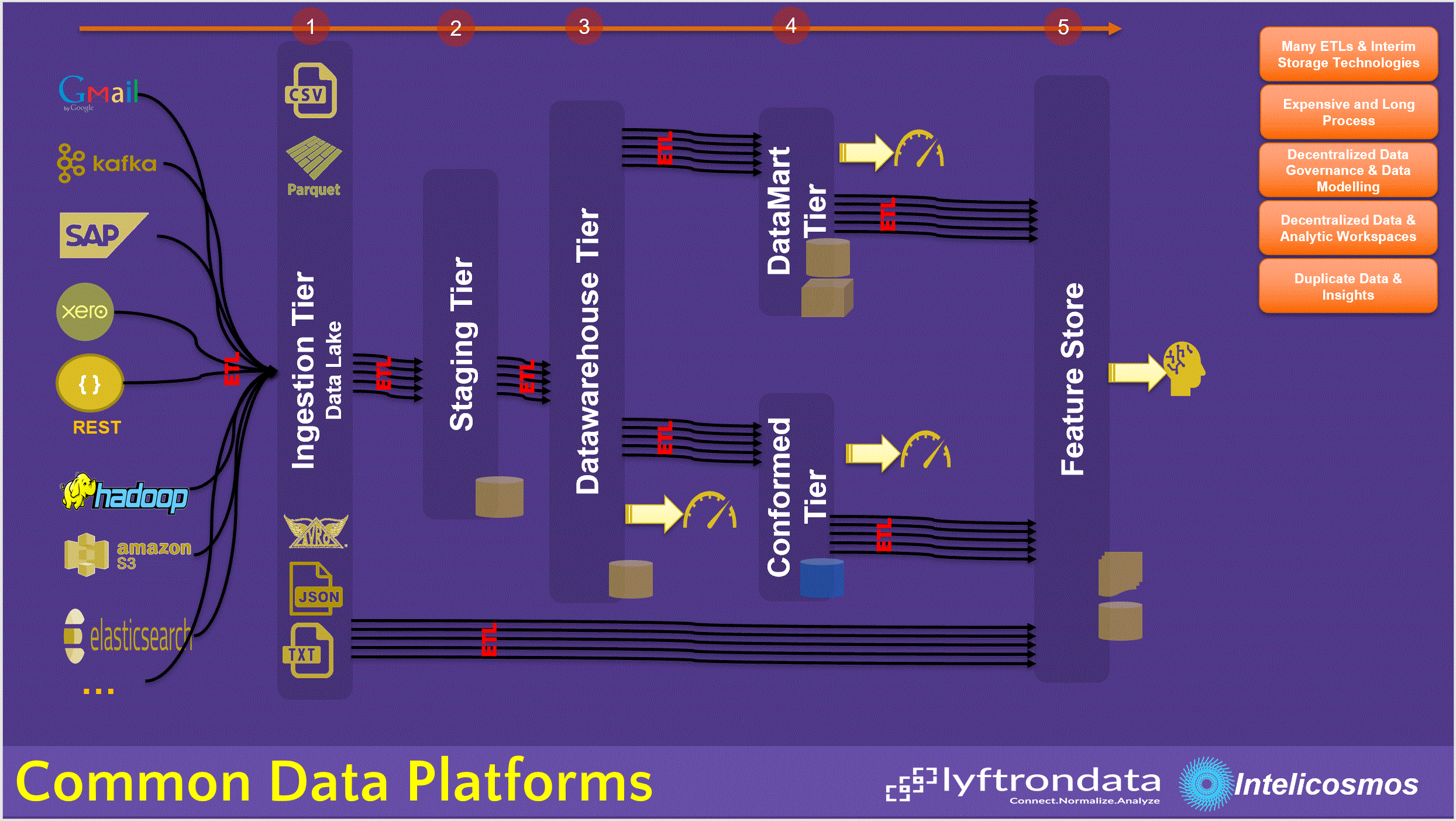
In our current BI and Advanced Analytic contexts, we can also find other topics like Conformed, ODS, Feature Store etc and I am not going to explore them here and I only provide some links.
Data Virtualization
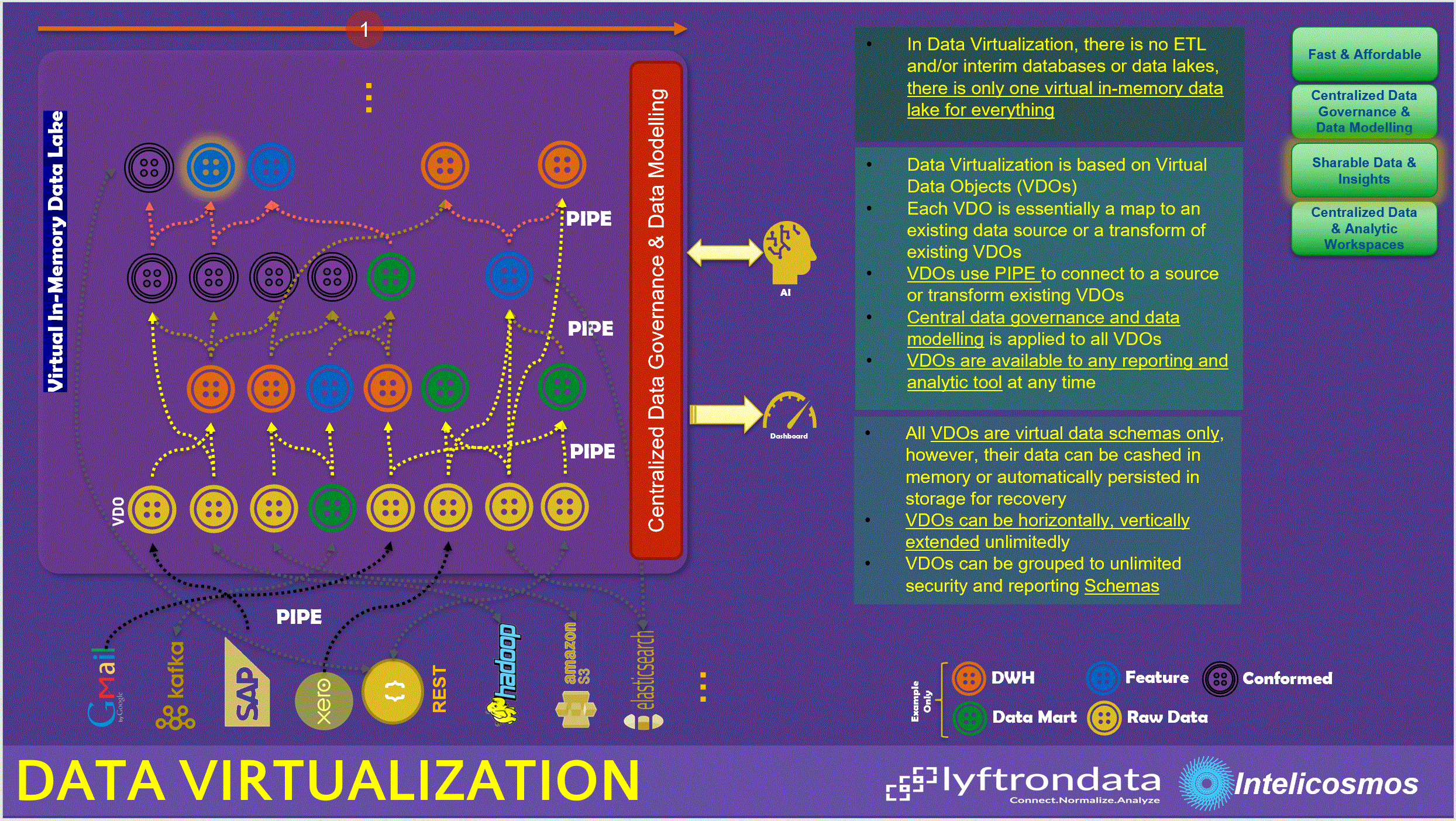
Data Virtualization is a new technique that dictates a zero or minimum data shuffling, replications, duplication, ETLs and interim layers while all business needs are still supported. In-fact, with Data Virtualization, we let data to sit where it belongs to and there is no need to move data from one place to another place just because we need a new data model.
Data Virtualization is based on below principals:
- Instead of separate physical data lake, staging, data warehousing, data marts or conformed layers, only one virtual in-memory data lake supports all use cases
- Tables, views, data frames, RDDS or data sets, whatever we call it, are replaced by Virtual Data Objects (VDOs)
- VDOs are essentially the schema of downstream data. This downstream data could be source tables, views, files, API payload, message etc or existing downstream VDOs
- VDOs establish a PIPE to downstream data to extract the schema and if needed, cache the downstream data into Data Virtualization platform
- VDOs can be built on top of existing VDOs
- VDOs can be dropped into separate logical groups to simulate security schemas and/or virtualize data warehouse, data mart, conformed etc layers, internally
- Data governance, data modelling, data security, data classification, data dictionary, data lineage and administration are centralized in Data Virtualization platform
- VDOs are accessible by all visualization or machine learning tools. With Data Virtualization, data modelling is centralized, therefore organizations don’t need to replicate data models when they switch to different visualization tool
- Data Virtualization acts as a real Data Hub, as all VDOs regardless of their state, will be accessible and sharable through ODBC and API
- VDOs can act as real ETL pipelines if needed (in most Data Virtualization use cases it is not required) to load data into physical targets
Lyftrondata
Lyftondata is a real Data Virtualization platform that supports above principals. Below is an example of Data Virtualization in Lyftrondata.
Let's have a look at key Data Virtualization capabilities available in Lyftrondata platform:
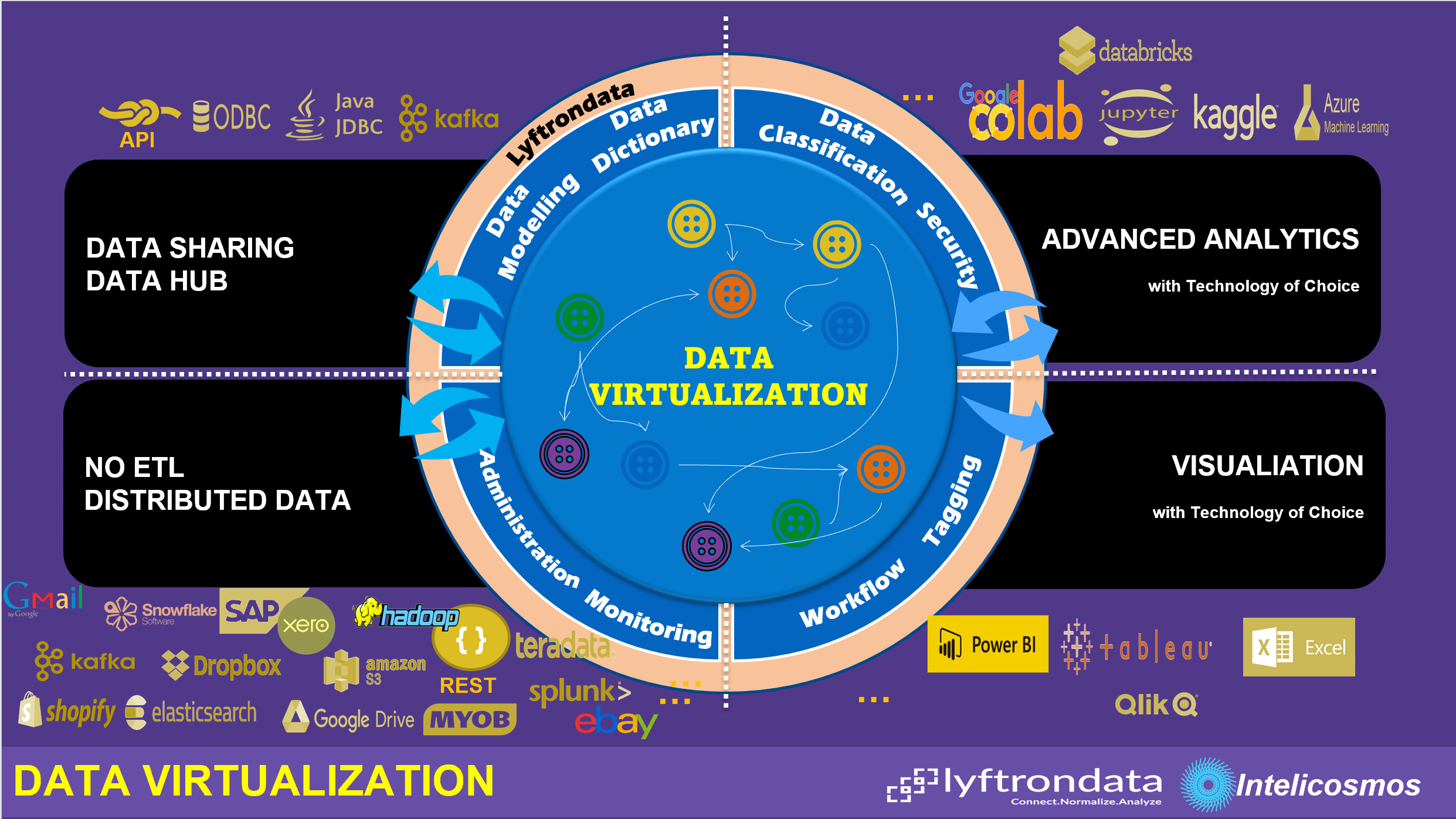
- NO ETL: In Lyftondata platform, VDOs can be built on more than 300 data sources without a real need to generate an ETL pipeline. Cross data source query is supported without a single ETL.
- Visualizaion Tools: Lyftondata platform supports ODBC, JDBC and API connectivity and connecting to Lyftondata through ODBC is similar to connecting to a SQL Server, so all visualization tools like PowerBI, Tableau, Excel etc can easily connect to the virtual environment and access VDOs. Well ofcourse, access will be based on fine grain security. As virtual data models are built in Lyft platform, all visualization tools can easily benefit from shared data models instead of building from scratch.
- Advanced Analytics: Machine learning and advanced analytic is also supported by Lyftondata platform. While Lyftondata platform is promoting Google Colab, Kaggle and Jupyter nootbok, infact, any nootbok like Azure ML or Databricks can esily connect to Lyftondata platform based on ODBC, JDBC or API. For example, one can use Python's Pyodbc and connect to Lyftondata platform from any tool.
- Data Sharing / Data Hub: I will explore Data Sharing and Data Hub within another article, but in a nutshell, Lyftondata platform is a real Data Hub as VDOs are accessible to authorized people/systems based on ODBC, JDBC or API. Also, VDOs can be shared to people/systems who are registered in Lyftondata platform or have Azure AD account (needs Lyftondata platform to be configured for Azure AD).
- Data Classification: I explained the Data Classification through Data Governance with Data Virtualization article, but just for now, any connection, data source, a VDO or part of VDO can be classified per classification tags available in Lyftondata platform
- Data Security: In Ltfrondata, we can grant people/systems to a connection, a source or target, a VDO or to its individual attributes. Admin or fine grain privilages (like Delete, Insert, Select, View etc) can be easily configured.
- Data Dictionary: Lyftondata is a Data Virtualization platform and all objects are logical and metadata is built automaically, that means, as we create our VDOs, data dictionary gets also generated and updated without anyone's action. Through a Data Catalog user interface, we are able to search for VDOs or their attributes based on keyword, a classification code etc.
- Data Modelling: A Data Virtualization platform enables us to generate logical data models on VDOs. We have had opportunity to generate physical data models on RDMSs, but such capability is not available on unstructured data like CSV, Avro, JSON, WebPage etc. Lyftrondata enables us to genearte such logical data models (including primary keys, unique keys, foreign keys, virtual columns etc) for the purpose of visualization, simulating a data warehouse and so far.
A centralized data modeling also helps organisations to benefit from shared data model for different visualization and/or advanced analytics instead of building self-managed data models. If we build a data model in PowerBI, that can't be used by Qlick for example, but a shared data model in Data Virtualization platform is accesible by anyone. - Data Tagging: Custom Key-Value tagging is available in Lyftondata on everything like connection, VDO etc.
- Workflow/Pipeline Management: As explained earlier, VDOs can be built without need to laod data, however, if data is needed, VDOs can be configured to cache data (batch, incremental or stream) into virtual datalake, or a VDO can load data to a designated target (acting as a real ETL if needed). A workflow can be setup to cache VDOs data in a required sequence.
- Monitoring/Administration: Centralized monitoring is available in Lyftondata to enable adminstrator to view and administrator the activities are running in the platform
A Data Virtualization Scenario in Lyftrondata
In the left side of the below image, we have our raw data which are distributed in different technologies of different cloud vendors. On the right side also, we have Snowflake cloud data warehouse of a partner company and we agreed to load data into that environment, however at the same time, that Snowflake cloud data warehouse is a source for our Data Virtualization platform also.
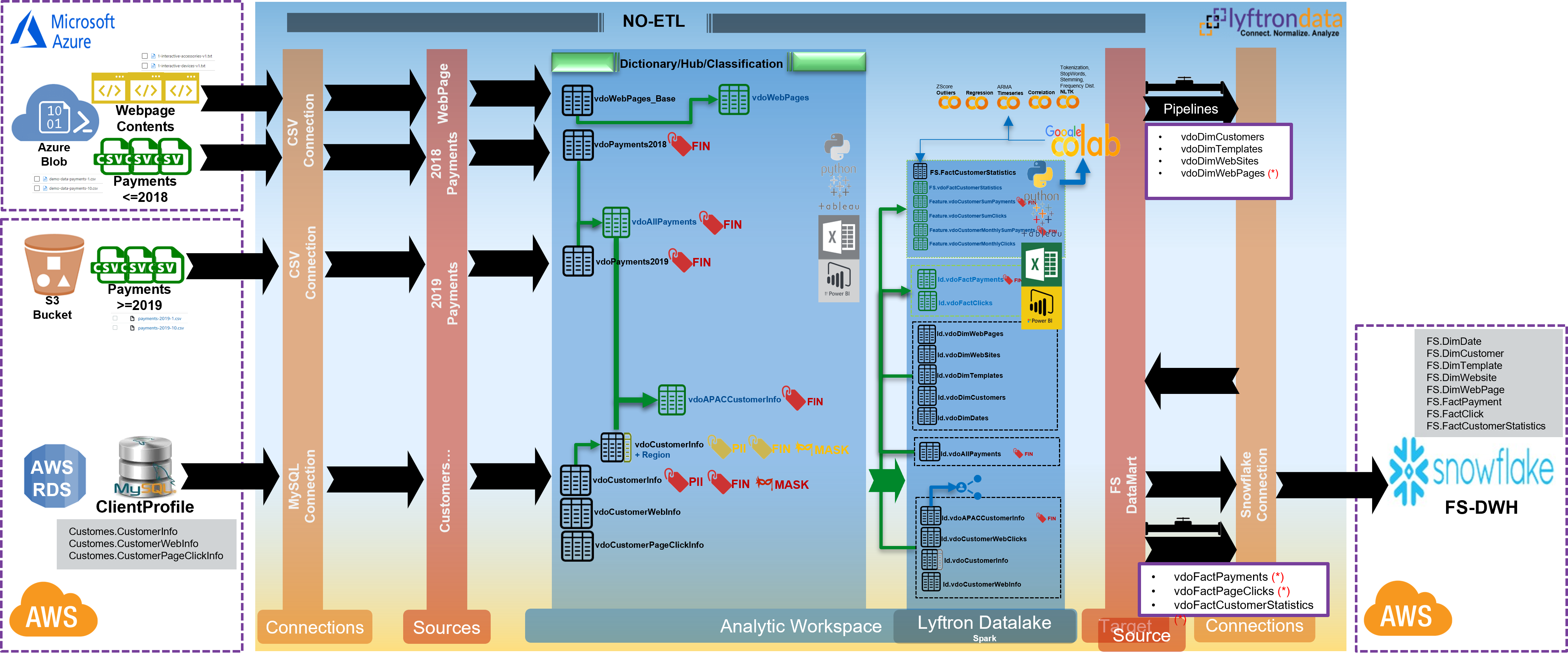
Without shuffling or replicating data from sources to anywhere, we can build our first level of VDOs and then expand them for more and more VDOs. As picture explains, Data Governance is available all the time and VDOs are accessible to visualization and machine learning tools regardless of their underlying technology as far as they can support T-SQL.

Ali Aghatabar, founder and director of Intelicosmos®, has been helping clients across the globe, particularly the APAC region, for over two decades. With a consulting background, he helped a wide range of clients and industries for their IT needs specially on data & analytic, cloud architecture and computing, AI and process automations, digital transformation, IoT and smart devices etc.